🧠 Arquitectura de Automate External Tms Loads
🌐 Visión General
El microservicio Automate External Tms Loads está diseñado como un componente clave dentro de una arquitectura de sistemas más amplia en GLT. Su función principal es automatizar el procesamiento de los Bills of Lading (BOLs) que llegan por correo electrónico, orquestando una serie de pasos que involucran la comunicación con múltiples servicios externos para finalmente actualizar la plataforma CRM de SalesForce.
El diseño interno se adhiere a una Arquitectura de Microservicios y se basa en dos patrones de diseño principales que definen su comportamiento: la Orquestación de Servicios y una Arquitectura Orientada a Eventos.
Arquitectura de Microservicios
-
¿En qué consiste?: Es un enfoque de desarrollo de software en el que una aplicación se construye como un conjunto de servicios pequeños y autónomos. Cada servicio se ejecuta en su propio proceso y se comunica con otros a través de APIs bien definidas. Este enfoque permite que los servicios se desarrollen, desplieguen y escalen de forma independiente.
-
¿Cómo se usa en el proyecto?: Este servicio es uno de los muchos microservicios que operan dentro del ecosistema de GLT. Funciona de manera independiente y se enfoca en una única responsabilidad de negocio: procesar los BOLs de Primus. Se comunica con otros microservicios (como Megatron API) y servicios de plataforma (como CRM API y Graph API) para cumplir su objetivo, sin estar fuertemente acoplado a ellos.
Orquestación de Servicios
-
¿En qué consiste?: En este patrón, un servicio central (el orquestador) es responsable de dirigir y coordinar la interacción entre varios servicios para ejecutar un flujo de trabajo complejo. El orquestador conoce el orden y la lógica de las llamadas, centralizando el control del proceso de negocio.
-
¿Cómo se usa en el proyecto?: Este es el patrón central del microservicio. La lógica de orquestación reside principalmente en el endpoint
POST /fetch-dataload(definido enapp/api/process.py). Cuando se invoca, este endpoint actúa como el director de orquesta, llamando secuencialmente a los diferentes clientes de servicio enapp/services/en un orden específico:- Leer correos (
mail_client). - Extraer datos del PDF (
agent). - Obtener información de APIs externas (
primus_client,crm_client). - Realizar cálculos (
megatron_client). - Crear o actualizar registros en el CRM (
crm_client).
- Leer correos (
Arquitectura Orientada a Eventos (Event-Driven)
-
¿En qué consiste?: Es un paradigma en el que el flujo del programa está determinado por eventos, como acciones del usuario, mensajes de otros servicios o, en este caso, temporizadores. Los componentes del sistema reaccionan a estos eventos de manera asíncrona.
-
¿Cómo se usa en el proyecto?: Aunque el proceso puede ser iniciado manualmente a través del endpoint, el diseño principal del servicio es operar de forma autónoma. Esto se logra a través de un planificador de tareas (
scheduler) ubicado enapp/scheduler/jobs.py. Este componente emite un "evento" basado en tiempo (por ejemplo, cada 5 minutos) que invoca automáticamente al orquestador. Esto desacopla el inicio del proceso de una llamada directa, permitiendo que el servicio monitoree y procese nuevos BOLs de manera proactiva y continua.
🔁 Flujo de una Solicitud
El siguiente diagrama ilustra el flujo de trabajo completo desde que se recibe un correo electrónico hasta que se crea o actualiza un LOAD en SalesForce.
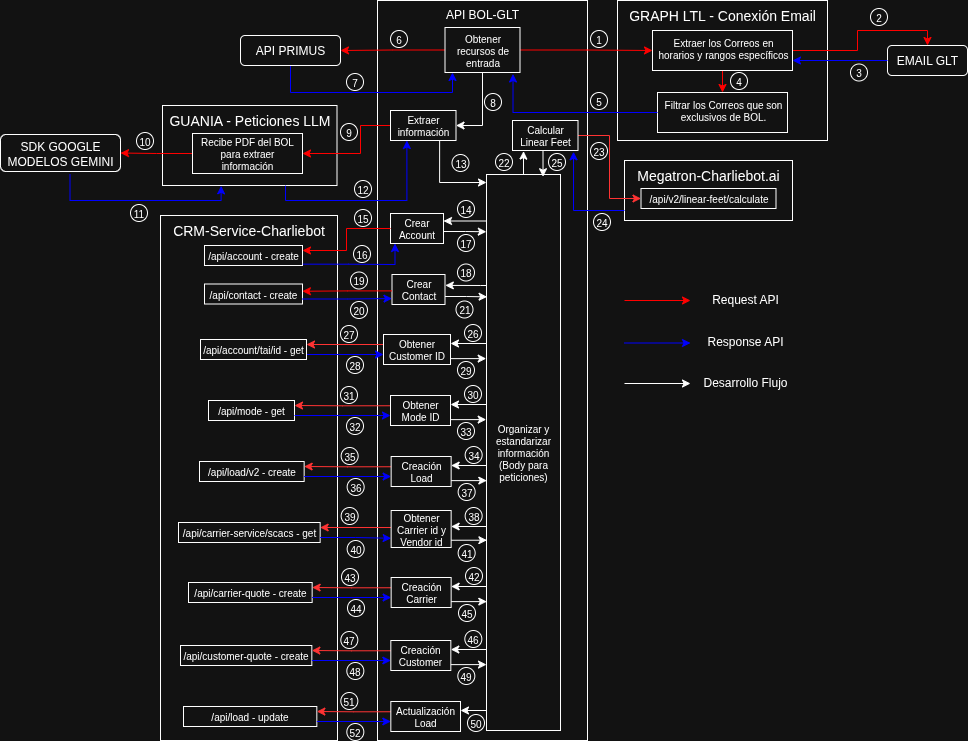
El proceso detallado es el siguiente:
- Inicio del Proceso: El
schedulero una llamada manual al endpointPOST /fetch-dataloadinicia el flujo. - Lectura de Correos: El
mail_clientse conecta a la Graph API para buscar correos no leídos que cumplan con los criterios (remitente y asunto). - Descarga de BOLs: Por cada correo encontrado, se descargan los archivos PDF adjuntos (los BOLs).
- Extracción de Datos con IA: Cada PDF es enviado al módulo
agent(app/services/agent/), que utiliza Vertex AI (Gemini) para extraer información clave del documento de forma estructurada. - Enriquecimiento de Datos: La información extraída se utiliza para consultar otros servicios:
- Primus API: Se obtienen datos adicionales del booking.
- CRM API: Se verifica si las cuentas o contactos ya existen en SalesForce.
- Mapeo de Datos: El
mapper(app/services/mapper/) transforma y consolida los datos obtenidos de todas las fuentes en un modelo de datos unificado que el sistema puede manejar. - Cálculos de Negocio: Se invoca a la Megatron API para realizar cálculos especializados, como los linear feet.
- Actualización del CRM: Finalmente, el
crm_clientutiliza los datos consolidados y calculados para crear o actualizar las entidades correspondientes (Cuentas, Contactos, Loads) en SalesForce.
🗂️ Estructura de Directorios
La estructura del proyecto está organizada para separar claramente las responsabilidades de cada componente.
app/
├── main.py
├── api/
│ └── process.py
├── core/
│ ├── config.py
│ ├── exceptions.py
│ ├── logging.py
├── models/
│ └── app_state.py
│ └── schemas.py
├── scheduler/
│ └── jobs.py
└── services/
├── agent/
│ ├── utils/
│ └── genia_client.py
│ └── process_pdf.py
├── mapper/
│ └── mapper.py
├── mail_client.py
├── crm_client.py
├── megatron_client.py
└── primus_client.py
└── send_email.py🔧 Componentes Principales
1. 🧩 Capa de API (app/api)
- Propósito: Define la interfaz pública del microservicio y actúa como el punto de entrada para las solicitudes.
- Tecnologías: FastAPI.
- Responsabilidades:
- Exponer los endpoints HTTP (en este caso,
POST /fetch-dataload). - Recibir solicitudes, validarlas usando los modelos de Pydantic y pasar el control al orquestador de servicios.
- Contiene la implementación principal de la orquestación que coordina las llamadas a los diferentes servicios en
app/services.
- Exponer los endpoints HTTP (en este caso,
2. 📓 Core (app/core)
- Propósito: Contiene la lógica y configuración transversal que es utilizada por toda la aplicación.
- Tecnologías: Nativas de Python.
- Responsabilidades:
config.py: Cargar y gestionar la configuración de la aplicación desde variables de entorno.logging.py: Configurar el sistema de logging para registrar eventos y errores.exceptions.py: Definir clases de excepciones personalizadas para un manejo de errores más granular.
3. 📐 Esquemas (app/models)
- Propósito: Definir la estructura de los datos que maneja la aplicación.
- Tecnologías: Pydantic.
- Responsabilidades:
schemas.py: Contiene los modelos de Pydantic que definen los esquemas para la validación de datos de entrada/salida de la API y para las estructuras de datos internas.app_state.py: Gestiona el estado de la aplicación, como los clientes de servicio compartidos, para evitar reinicializarlos en cada solicitud.
4. ⏲️ Scheduler (app/scheduler)
- Propósito: Implementar la funcionalidad de ejecución de tareas programadas.
- Tecnologías: APScheduler (o una librería similar).
- Responsabilidades:
jobs.py: Define y configura la tarea periódica que invoca al endpoint de procesamiento de BOLs, implementando así el patrón de arquitectura orientada a eventos.
5. 🛠️ Services (app/services)
- Propósito: Alberga la lógica de negocio principal y la comunicación con los sistemas externos.
- Tecnologías: HTTPX (para clientes asíncronos), Vertex AI SDK.
- Responsabilidades:
- Clientes de API: Cada
*_client.pyes responsable de la comunicación con un servicio externo específico (CRM, Primus, etc.). Encapsula la lógica de las llamadas de red, el manejo de la autenticación y la gestión de errores. - Módulo
agent: Contiene la lógica para interactuar con la IA de Google.genai_client.pyse comunica con el modelo, mientras queprocess_pdf.pyorquesta la extracción de datos del documento. - Módulo
mapper: Actúa como una capa de transformación (anti-corrupción). Convierte los datos de los formatos de las APIs externas a los modelos internos definidos enapp/modelsy viceversa, manteniendo el núcleo de la aplicación desacoplado de los sistemas externos.
- Clientes de API: Cada